DataSango vs 主要データ品質ツール6社徹底比較 2026|「名寄せ」と「マージ」を峻別して選ぶ最適解
CRMのデータ品質ツールを比較する際、業界で最も誤解されているのが「名寄せ」と「マージ」の混同です。本記事では両者を厳密に定義した上で、Sansan Data Hub/uSonar/FORCAS/DataSango/Insycle/Salesforce標準/HubSpot Data Hubの実態を比較。DataSangoは名寄せ・クレンジング・エンリッチ・トランスフォーム・マージの全レイヤーをカバーし、各機能のON/OFFをユーザー側で選べるため、監査要件や履歴保持が必須のケースにも適用可能——AI Agent / MCP連携時代に「自社の運用ポリシーに応じてどう使い分けるか」を見極める判断軸を提示します。

はじめに:データ品質ツール比較で最も誤解されている1点
CRMのデータ品質ツールを検討する企業の8割以上が、「名寄せ」と「マージ」を同じ意味で捉えています。これは業界全体の用語使いが曖昧なためで、ベンダーのマーケティング資料も「名寄せ」「統合」「自動化」を混在させて記述する傾向にあります。
しかし両者は技術的にも、運用上も、得られる成果も根本的に異なる処理です。この区別なしにツールを選ぶと、「導入したのにレコードが減らない」「運用負荷が下がらない」「監査要件と衝突する」といった事態に必ず直面します。
本記事ではまず「名寄せ vs マージ」を厳密に定義し、その上で主要7ツール(DataSango/uSonar/Sansan Data Hub/FORCAS/Insycle/Salesforce標準/HubSpot Data Hub)の対応範囲を整理します。AI Agent / MCP連携が本格化した2026年において、データ品質投資はAI活用ROIを左右する戦略投資になっており、用語を曖昧にしたまま進めることのリスクは年々高まっています。
編集方針: 競合の設計思想と強みを率直に記載しています。最終的な選定はぜひ複数ツールの無料トライアルで自社データを実テストした上で行ってください。
第1章:「名寄せ」と「マージ」の正しい定義
この2つは別の処理である
| 内容 | 処理結果 | レコード数 |
|---|---|---|---|
名寄せ(Identity Resolution) | 複数レコードが同一企業/人物と判定し、共通キー(コード)を付与する。同時に属性情報も付与する | コードで論理的に紐付く | 減らない |
マージ(Merge) | 重複と判定したレコードを実際に統合・削除して1件に集約する物理処理 | 元データは原則消える | 減る |
図解:処理結果の違い
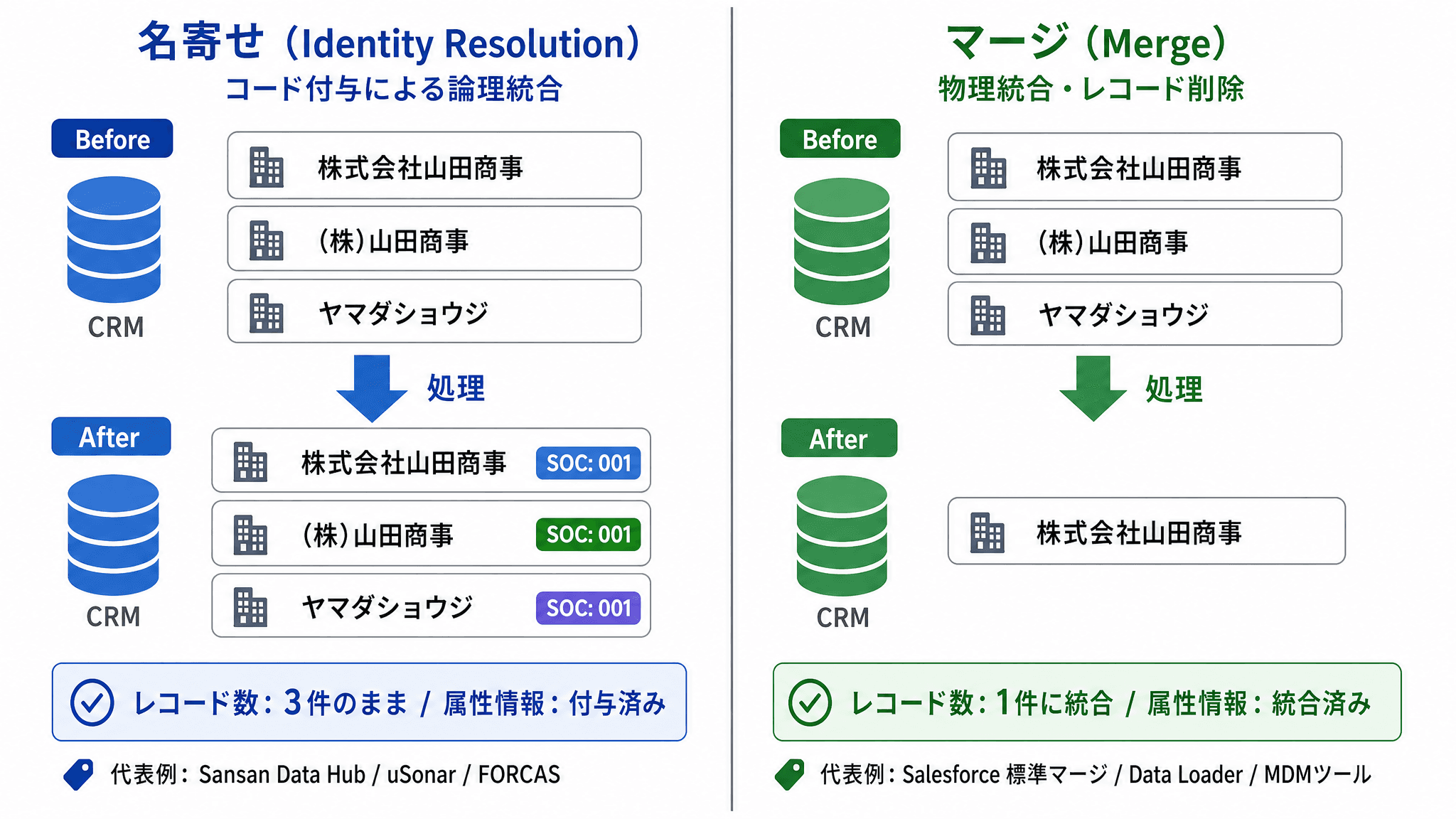
図1. 「名寄せ」はコードを付与してレコードを論理的に紐付ける処理、「マージ」は物理的にレコードを統合・削除する処理。両者は別物。
なぜこの違いが重要なのか
名寄せは大企業のデータガバナンス文化に適合します。監査要件で物理削除が許されない、履歴を残したい、勝手にレコードを消されると困る——こうした制約下では「コードで論理的に紐付ける」が正解です。
マージは中堅・成長企業の運用負荷削減に直結します。CRM画面に重複が見えていると営業現場が混乱する、商談カウントが二重になる、レポートの数字が信頼できない——こうした課題には「物理的に統合・削除する」が正解です。
業界の混乱の根源は、両者を「自動データ統合」「クレンジング」と一括りにマーケされていることにあります。本記事では、この混同を解きほぐして整理します。
そしてもう一つ、ツール選定で見落とされがちな観点が 「両方を選べるか」 です。後述しますが、DataSangoは名寄せもマージも両方カバーし、マージ機能のON/OFFをユーザー側で選択できるため、ガバナンス重視運用と運用負荷削減運用のどちらにも適合できる設計になっています。
第2章:データ品質処理の5レイヤーと、各社の対応範囲
ここで重要な視点を導入します。データ品質処理は5つのレイヤーに分解できます。
アイデンティティ・レゾリューション(コード付与・名寄せキー付与)
エンリッチメント(属性情報の付与・補完)
クレンジング(表記ゆれの正規化)
トランスフォーム(複数条件から新カラム生成・履歴保持)
物理マージ実行(重複レコードの統合・削除/オプション選択可)
各社がどのレイヤーをカバーしているかを整理すると、競合構造が一気に見えてきます。
ツール | L1 名寄せ | L2 エンリッチ | L3 クレンジング | L4 トランスフォーム | L5 物理マージ |
|---|---|---|---|---|---|
DataSango | ◎ | ◎ | ◎ | ◎ 独自領域 | ◎ |
uSonar | ◎ LBC | ◎ LBC連携 | ◎ | △ | ✕ 範囲外 |
Sansan Data Hub | ◎ SOC | ◎ 50属性+ | ◎ | △ | ✕ 範囲外 |
FORCAS | ◎ FORCAS ID | ◎ 150万社+ | ◎ | △ | ✕ 範囲外 |
Insycle | ◎ | △ 外部API | ◎ | ○ | ◎ |
Salesforce 標準 | ○ | ✕ | ✕ | ✕ | △ 手動 |
HubSpot Data Hub | ○ | ○ | ○ | ○ | ○ |
この表が示す本質
DataSangoはL1〜L5の全レイヤーをカバーする国内ツールです。一方、国内主要3社(Sansan Data Hub / uSonar / FORCAS)はL1〜L3が主戦場で、L4トランスフォーム・L5物理マージは別領域として整理されています。
そしてDataSangoのL5物理マージに関しても、ON/OFF選択可能なオプションであり、必ず使わなければならないわけではない——この設計上の柔軟性が後述するユースケース別推奨で決定的な意味を持ちます。
第3章:国内主要3社の実態 ― Sansan Data Hub / uSonar / FORCAS は何をしているのか
結論
国内主要クレンジングSaaS3社のコア機能は「アイデンティティ・レゾリューション + 属性エンリッチメント」であり、CRM上のレコードを物理的にマージ削除するアクションは標準範囲外です。
Sansan Data Hub の実態
公式説明を精読すると、Sansan Data Hubの動作は以下です。
「外部システム上の顧客データを高度な名寄せ技術で識別し、企業を特定。特定された企業には、Sansan独自の企業コード(SOC:Sansan Organization Code)が付与され、このコードを活用することで、重複データの特定や統合といったクレンジング作業を大幅に効率化します」 entry.sansan.com
ポイントは:
やっていること: SOCの付与+属性情報の付与+コードによる論理的紐付け
やっていないこと: CRM上の重複レコードの物理マージ・削除実行
「重複データの特定や統合作業を効率化する」という表現は、マージ判断の材料を提供する意味であって、マージそのものを実行するわけではない
JBS社事例で「4200件の重複が解消」とありますが jp.sansan.com、これはSOCで論理的に同一判定された結果を指す表現で、最終的なマージ実行はCRM側機能か別途運用で行われています。
uSonar の実態
uSonarも同じ構造です。
「LBCを辞書とすることにより、法人顧客やリードデータを高精度にクレンジング、名寄せします」 usonar.co.jp
「LBCコードにより、資本関係(親子会社)、拠点関係(本店ー事業所)を可視化」 2025年12月期決算説明資料
ポイントは:
やっていること: LBCコードの付与+属性付与+資本/拠点関係の可視化
やっていないこと: CRM上のレコード物理マージ実行
「メンテナンス工数ゼロ」「自動更新」というマーケ表現は、LBC側マスタの更新がCRMに追従反映される意味であって、重複レコードが消えるわけではない
FORCAS の実態
FORCASも企業ID付与による名寄せ+エンリッチメントが中核 g-gen.co.jp で、CRM上のレコード物理マージは標準動作ではありません。150万社以上の企業DBを活用した属性付与とABM支援が主用途です。
国内3社の共通構造
[国内クレンジングSaaS3社の動作モデル]
CRMからレコードを取り込む
自社の企業マスタDB(SOC/LBC/FORCAS ID)と照合
同一判定したレコード群に「共通コード」を付与
同時に属性情報(業種・従業員数・住所等)を付与
CRM上のレコード自体は減らない(=論理統合に留まる)
物理マージは CRM 側機能 or 別途運用に委ねる
これは設計の不備ではなく、大企業のガバナンス要件に適合した合理的な設計思想です。監査・履歴保持を必須とする企業には、むしろこの設計が望ましい。
第4章:DataSango が踏み込んでいる領域 ― 全レイヤー対応 + 運用ポリシー選択
DataSango の本質:マージ「型」ではなく、フルレイヤー対応型
DataSangoは国内3社(Sansan Data Hub / uSonar / FORCAS)が主戦場とするL1〜L3レイヤーをカバーした上で、さらにL4トランスフォームとL5物理マージ実行までを一気通貫で提供する設計です。
ここで決定的に重要なのは、ユーザー側で運用ポリシーを選択できる点です。
運用ポリシー | 動かす機能 | 適合する企業 |
|---|---|---|
ガバナンス重視運用 | L1〜L4のみ(マージOFF) | 監査要件あり/履歴保持必須の中堅〜大企業 |
運用負荷削減運用 | L1〜L5すべて(マージON) | CRM画面の重複を物理的に解消したい中堅・成長企業 |
ハイブリッド運用 | オブジェクト別にL5のON/OFFを切替 | 取引先=マージOFF、リード=マージONなど使い分け |
つまりDataSangoは「マージ型」というラベルに収まらず、企業のガバナンスポリシーに合わせて使う機能を選べるフルレイヤー型ツールです。
DataSangoの履歴保持機能:トランスフォームの設計思想
特筆すべきは、L4トランスフォーム機能が履歴保持型として設計されている点です。
DataSango公式の機能説明には以下が明記されています:
「元データを書き換えるのではなく、新カラムに変換結果を出力」
「既存フィールドは変更せず、構造化された別フィールドを自動更新」
つまりDataSangoでL4トランスフォームを動かしても元データは保護されるため、監査要件や履歴保持を必須とする企業でも安心して運用できます。これはガバナンス重視文化への深い配慮を反映した設計です。
DataSango独自のL4トランスフォーム機能
L4トランスフォームの具体例:
「業種=IT かつ 従業員100名以上 → セグメントA」のような複数条件から指定カラムを自動更新
AIトランスフォームでは「社長」「代表取締役」「CEO」のような自由記述を意味解釈して構造化分類
元データを書き換えず別カラムに出力する履歴保持型設計
国内3社(Sansan / uSonar / FORCAS)は属性付与中心、Salesforce/HubSpotには数式項目があるものの複雑条件のノーコード設計UIではDataSangoが優位です。
Insycle との違い
L5物理マージまで踏み込んでいるツールはDataSangoとInsycleですが、Insycleは英語圏HubSpot/Salesforce向けに最適化されており、日本企業特有の表記対応・AI意味解釈・トランスフォームの履歴保持設計はDataSangoが優位です。
第5章:機能・価格・対象企業の総合比較表
評価軸を「コード付与(名寄せ)」と「物理マージ実行」に分離し、トランスフォーム機能を独立列として明示しました。
評価軸 | DataSango | uSonar | Sansan Data Hub | FORCAS | Insycle | Salesforce 標準 | HubSpot Data Hub |
|---|---|---|---|---|---|---|---|
国 / 提供元 | 🇯🇵 株式会社Mer | 🇯🇵 ユーソナー | 🇯🇵 Sansan | 🇯🇵 ユーザベース | 🇺🇸 Insycle Inc. | 🇺🇸 Salesforce | 🇺🇸 HubSpot |
企業DB搭載 | 国内500万社+ | 国内820万件規模のLBC | 名刺起点の独自DB+SOC | 150万社+ FORCAS ID | なし | なし | △ |
L1 アイデンティティ・レゾリューション(コード付与) | ◎ ルール+AI | ◎ LBCコード | ◎ SOC | ◎ FORCAS ID | ◎ | ○ 標準ルール | ○ |
L2 属性エンリッチメント(情報付与) | ◎ 国内500万社+AI | ◎ LBC連携 | ◎ 50属性+ | ◎ 150万社DB | △ 外部API依存 | ✕ | ○ |
L3 表記ゆれクレンジング | ◎ ルール+AI | ◎ LBC基準で正規化 | ◎ | ◎ | ◎ | ✕ | ○ |
L4 トランスフォーム(履歴保持型・別カラム出力) | ◎ 複数条件→指定カラム自動更新 | △ 属性付与中心 | △ 属性付与中心 | △ 属性付与中心 | ○ Transform Data モジュール | △ | △ |
L5 物理マージ実行(レコード統合・削除/オプション) | ◎ ON/OFF選択可・スケジュール自動実行 | ✕ 範囲外(CRM側運用) | ✕ 範囲外(CRM側運用) | ✕ 範囲外(CRM側運用) | ◎ ON/OFF選択可・スケジュール自動実行 | △ 1件ずつ手動マージ | ○ ワークフロー連動 |
AIエンリッチメント(Web自動調査) | ◎ ニュース/採用等の定性情報など | ✕ | ✕ | ✕ | ✕ | ✕ | ○ Breeze連携 |
AIトランスフォーム(自由記述分類) | ◎ AIトランスフォーム | ✕ | ✕ | ✕ | ✕ | ✕ | △ |
料金 | 無料プラン有 | 要問合せ(高額帯) | 要問合せ(高額帯) | 要問合せ(高額帯) | $1〜/レコード | CRM料金内 | Hub料金内 |
日本語UI / サポート | ◎ | ◎ | ◎ | ◎ | ✕ 英語のみ | △ | ○ |
設計思想 | フルレイヤー対応・運用ポリシー選択可 | ガバナンス重視型 | ガバナンス重視型 | ABM/マーケ重視型 | 運用負荷削減型 | CRM内蔵型 | CRM内蔵型 |
想定ターゲット | 中小〜大企業(運用ポリシー次第で全層対応) | 中堅〜大企業 | 大企業中心 | 中堅〜大企業 | グローバル中堅 | SF導入企業 | HS導入企業 |
※2026年5月時点の公開情報ベース。
この比較表が示す本質
国内主要3社(Sansan Data Hub / uSonar / FORCAS)はL1〜L3レイヤーで戦っており、L4トランスフォーム・L5物理マージは別領域として整理されています。
DataSangoはL1〜L5の全レイヤーに対応し、各機能のON/OFFをユーザー側で選択できる設計であるため、ガバナンス重視運用にも運用負荷削減運用にも適合します。これが「マージ型ツール」というラベルに収まらない本質です。
第6章:自社が必要としているのは「名寄せ」か「マージ」か、それとも「両方」か
判定フローチャート
Q1. 自社のデータガバナンス要件は?
├─ 監査要件で物理削除NG / 履歴保持必須
│ → 名寄せ型(Sansan Data Hub / uSonar / FORCAS)
│ → または DataSango(マージOFF設定 + L4トランスフォームで履歴保持)
│
└─ 物理削除OK / 運用負荷削減を優先
→ DataSango(マージON)
→ または Insycle(英語環境のみ)
Q2. CRM画面に重複が見えていることが業務阻害になっているか?
├─ Yes → DataSango(マージON)/ Insycle
└─ No → 名寄せ型でも DataSango(マージOFF)でも可
Q3. 1年以内にAI Agent / MCP連携を計画しているか?
├─ Yes → AIトランスフォーム機能のあるDataSangoが優位
└─ No → ルールベースでも当面OK
Q4. 自社固有の戦略指標をカラムで自動更新したいか?
├─ Yes → AIトランスフォーム・AIエンリッチメント機能あり(DataSango)
└─ No → 不要(ただしDataSangoは使わない選択もOK)
ポイントは、Q1のどちらの分岐にもDataSangoが選択肢として登場することです。これはDataSangoが運用ポリシー選択型であるためです。
ユースケース別の推奨
自社の状況 | 推奨ツール | 補足 |
|---|---|---|
大企業・全社マスタ統合・監査要件あり | uSonar / Sansan Data Hub / DataSango(マージOFF + L4履歴保持運用) | DataSangoはマージOFFで論理統合 + 新カラム出力 |
名刺起点でデータ基盤を作りたい | Sansan Data Hub / DataSango(併用可) | 名刺資産活用が必要なら Sansan、CRM運用層は DataSango |
ABM・マーケ用途の企業DB拡張 | FORCAS / uSonar / DataSango | FORCAS/uSonarは業界DB特化、DataSangoはAI調査が強い |
中堅企業・CRM運用負荷を減らしたい | DataSango(マージON) | 物理マージ + トランスフォームで一気通貫 |
中小・成長企業・AI Ops本格運用 | DataSango | AI機能標準搭載 + 無料プラン |
海外子会社・英語環境のCRM運用 | Insycle | 英語環境特化 |
Salesforce導入直後・標準機能で十分 | Salesforce重複ルール / 将来的にDataSango | 成長してデータが増えたらDataSangoへ |
履歴保持必須+トランスフォームで戦略指標生成 | DataSango(マージOFF + L4運用) | 元データを書き換えず新カラム出力 |
監査要件あり+運用負荷も下げたい | DataSango(オブジェクト別ハイブリッド運用) | 取引先=マージOFF、リード=マージONなど |
全てのユースケースでDataSangoが選択肢として登場する——これは「フルレイヤー対応 + 運用ポリシー選択可」という設計の必然的な帰結です。
併用パターンも合理的
「名寄せ型 + マージ型」の併用も理論的に強力です:
uSonar / Sansan Data Hub でLBCコード/SOC を付与(マスタ統合レベル)
DataSango で L4トランスフォームと L5物理マージ(CRM運用レベル)
予算が許すなら、両レイヤーをカバーするのが日本市場で最も洗練された構成です。ただしDataSango単体でもL1〜L5の全レイヤーをカバーできるため、まずDataSangoで始めて必要に応じて国内3社のいずれかを追加する、という段階導入も合理的です。
第7章:DataSango vs Insycle ― L5物理マージ対応2社の比較
DataSangoとInsycleは設計思想が近いL5対応2社です。違いを精査します。
項目 | DataSango | Insycle |
|---|---|---|
提供言語 | 日本語フルサポート | 英語のみ |
対応CRM | Pipedrive、Salesforce、HubSpot他(広い) | Pipedrive、Salesforce、HubSpot他(広い) |
価格モデル | 無料プラン + 従量 + クレジットパック | レコード数課金(モジュール別 $1〜/月)Insycle G2 |
企業DB搭載 | 国内500万社+AI調査 | 自社DBなし(外部API連携) |
L4 トランスフォーム(履歴保持) | ◎ 元データを書き換えずカラム出力 | ○ ルールベース中心 |
L5 物理マージ実行 | ◎ ON/OFF選択可 | ◎ ON/OFF選択可 |
AIトランスフォーム/AIエンリッチメント | ◎ | ✕ |
日本企業特有の表記対応 | ◎ 株式会社/(株)/法人番号等 | ✕ 英語データ前提 |
Insycleが優れる点: 世界中のCRMユーザーで揉まれた成熟UI、HubSpot Marketplace公式統合、モジュール購入型の柔軟価格設計。
DataSangoが優れる点: 日本固有表記対応、日本語サポート、AI意味解釈、トランスフォームの履歴保持設計、L5マージのON/OFF選択(運用ポリシー柔軟性)。
第8章:Salesforce / HubSpot 標準機能では何が足りないのか
Salesforceの場合
Salesforce標準には重複ルール・一致ルールがあり、新規レコード作成時の重複検出・ブロックは可能 Salesforce Help。
ただし限界が3つあります:
既存データの一括マージが弱い — 重複は1件ずつ手動マージが前提。数万件の既存データ整備には不向き
表記ゆれ対応が苦手 — 「株式会社」「(株)」を同じものとして扱うルール設計は標準では困難
エンリッチメント・トランスフォームは外部依存 — 独自DB・複数条件カラム生成は標準範囲外
HubSpot Data Hubの場合
HubSpot Data Hub(旧Operations Hub)にはデータ品質オートメーションが搭載され、ワークフロー内で電話番号フォーマット統一などが可能 start-link.jp。
ただし限界が3つあります:
HubSpot Professional以上のプラン必須 — 中小企業の大半が使えない
日本企業データへの最適化不足 — 法人番号・日本独自表記対応が弱い
HubSpot外部CRMでは使えない — 他CRM使用中の企業には選択肢にならない
DataSangoが補完するレイヤー
DataSangoは標準機能の上に「国内特化DB + L4トランスフォーム + L5マージ(オプション) + AI解釈 + マルチCRM対応」を上乗せします。標準機能を否定するのではなく、その弱点を埋める補完層という位置づけです。
第9章:内製スクリプト vs SaaS導入の損益分岐点
結論
「データ整備に月20時間以上の人件費がかかっている」または「Pythonエンジニアの工数が月10時間以上奪われている」なら、SaaS導入の方が確実に安い。
試算モデル(中堅企業の典型ケース)
項目 | 内製スクリプト | DataSango |
|---|---|---|
初期構築 | エンジニア80時間 × 8,000円 = 64万円 | 0円〜(伴走支援オプション別) |
月次運用 | エンジニア20時間 × 8,000円 = 16万円 | 数万円〜 |
改修対応 | データ仕様変更ごとに発生(年4-6回) | ノーコードで業務担当者が変更可 |
トランスフォーム条件追加 | スクリプト改修必須 | UIでルール追加のみ |
AIエンリッチメント | 別途OpenAI API + 開発工数 | 標準搭載 |
年間コスト概算 | 約256万円 | 数十万円〜 |
追加リスク | エンジニア退職時に運用停止 | ベンダー継続性に依存 |
正直な但し書き: 自社にAIエンジニアが既に常駐していて、データ整備スクリプトが既に安定運用されている企業は無理に乗り換える必要はありません。内製の最大の強みは"完全な自由度"です。ただし大半の日本企業はこの条件を満たしません。
第10章:結論 ― 自社に合うツールを選ぶ3ステップ
Step 1: 「名寄せか、マージか、両方か」を決める
監査要件・履歴保持必須 → 名寄せ型(Sansan / uSonar / FORCAS)または DataSango(マージOFF運用)
運用負荷削減・物理レコード統合優先 → DataSango(マージON) または Insycle
両方欲しい → DataSango単体(フルレイヤー対応) または 国内3社+DataSango併用
Step 2: AI活用ロードマップとの整合性を確認
1年以内にAI Agent / MCP連携を計画 → DataSango優位(AI機能標準搭載)
ルールベースで当面十分 → どのツールでもOK
Step 3: 無料トライアルで自社データを実テスト
DataSango: クレジットカード不要・14日間 + 無料プラン継続可
Insycle: モジュール別トライアル
uSonar / Sansan / FORCAS: 営業経由のPoC
判断は1日で出さない。最低2週間、複数ツールを並走テストし、「名寄せだけで足りるか、マージまで必要か、両方使い分けたいか」を実データで検証してください。DataSangoの無料プランなら、マージOFF運用と マージON運用の両方を実機で試すことができます。
よくある質問(FAQ)
Q1. 「名寄せ」と「マージ」は何が違うのか?
A. 名寄せは複数レコードに共通キー(コード)を付与して論理的に紐付ける処理で、レコード数は減りません。マージは重複と判定したレコードを物理的に統合・削除する処理で、レコード数が減ります。両者は目的も設計思想も異なる別の処理です。大企業のガバナンス要件には名寄せが、中堅企業の運用負荷削減にはマージが適しています。
Q2. SansanやuSonarは重複マージを自動でやってくれるのか?
A. 結論:「名寄せ」はやるが「マージ」はやらないケースが基本です。Sansan Data Hub・uSonar・FORCASなど国内主要クレンジングSaaS3社のコア機能は、自社の企業マスタDBとCRMレコードを照合して共通コード(SOC / LBCコード / FORCAS ID)を付与するアイデンティティ・レゾリューションと、属性情報の付与です。CRM上の重複レコードを物理的に統合・削除するアクションは標準範囲外で、最終マージはCRM側機能や別途運用で実施します。これは大企業のガバナンス要件に適合した合理的設計思想です。
Q3. では「物理マージ実行」まで自動でやるツールはあるのか?
A. 国内ではDataSango、海外ではInsycleが代表的です。両者ともルール定義 + スケジュール自動実行で重複レコードの物理統合・削除を自動化します。中堅・成長企業がCRMの実レコード数を減らして運用負荷を下げたい用途に適しています。
Q4. DataSangoはマージ実行を必ず行わないといけないのか?
A. いいえ。マージ機能はオプションであり、ON/OFFを選択できます。監査要件や履歴保持が必須の企業は、マージOFF設定で「コード付与(L1)・エンリッチメント(L2)・クレンジング(L3)・トランスフォーム(L4)」のみを動かし、論理統合に留めることが可能です。さらにL4トランスフォーム機能は元データを書き換えず新カラムに結果を出力する設計のため、履歴保持型の運用にも適合します。オブジェクト別にON/OFFを切り替えるハイブリッド運用(取引先=マージOFF、リード=マージONなど)も可能です。
Q5. 監査要件があり物理削除NGの企業でもDataSangoは使えるか?
A. 使えます。DataSangoのL5物理マージ機能をOFFに設定すれば、L1〜L4の機能のみが動作し、CRM上のレコード数は変化しません。さらにL4トランスフォームは「元データを書き換えるのではなく、新カラムに変換結果を出力」「既存フィールドは変更せず、構造化された別フィールドを自動更新」という履歴保持型設計のため、監査・履歴保持要件と整合します。Sansan Data Hub・uSonar・FORCASのような名寄せ型運用と同等の「論理統合のみ」のポリシーで使えます。
Q6. DataSangoの「トランスフォーム機能」とは何か?他ツールとどう違うのか?
A. DataSangoのトランスフォーム機能は、複数カラムの条件を組み合わせたルールから指定したカラムを自動更新する機能です。例えば「業種=IT かつ 従業員100名以上 → セグメントA」のロジックをノーコードで定義しスケジュール自動実行できます。AIトランスフォームでは「社長」「代表取締役」「CEO」のような自由記述を意味解釈して構造化分類します。元データを書き換えず別カラムに出力する履歴保持型設計であり、Sansan / uSonar / FORCASは属性付与中心で自社ロジックでの新指標生成には弱く、Salesforce / HubSpotの数式項目より複雑条件のノーコード設計UIで優位です。
Q7. データクレンジングツール選定で見るべき5つの評価軸とは?
A. (1) 名寄せ型かマージ型か、または両方カバーか、(2) データソースカバレッジ、(3) AI活用度(ルールベースかAI意味解釈か)、(4) 運用ハードル(エンジニア要否)、(5) TCO(初期+月額+連携+人件費)。特に(1)を曖昧にしたまま選定すると「導入したのにレコードが減らない」「監査要件と衝突する」事態に陥ります。
Q8. Salesforce / HubSpot標準のデータ管理機能で足りない場合、DataSangoはどう補完するか?
A. Salesforce標準は新規レコード重複検出に強いものの既存データ一括マージが弱く、HubSpot Data HubはProfessional以上のプラン必須で日本企業データ最適化が浅いです。また両ツールともルール設計の柔軟さに難があります。DataSangoは国内500万社DB、L4トランスフォーム、L5物理マージ(オプション)、AIトランスフォーム、AIエンリッチメント、マルチCRM対応により両者の弱点を補完するレイヤーとして機能します。
Q9. 名寄せ型ツールとDataSangoは併用できるか?
A. 併用は理論的に強力な構成です。uSonar / Sansan Data Hubで全社マスタとしてLBCコード / SOCを付与し(論理統合レベル)、DataSangoでCRM運用レベルのL4トランスフォームとL5マージを担う構成が、日本市場で最も洗練されたデータ品質スタックの一つとなります。ただしDataSango単体でもL1〜L5の全レイヤーをカバーできるため、まずDataSangoで始めて必要に応じて段階導入する選択肢も合理的です。
Q10. 内製スクリプトでデータ整備するのとSaaS導入の損益分岐点は?
A. データ整備に月20時間以上人件費がかかっている、またはエンジニア工数が月10時間以上奪われているならSaaS導入が安いです。中堅企業の典型例で内製は年間約256万円、DataSangoは数十万円〜と試算され、エンジニア退職時の運用停止リスクも回避できます。


